细心的用户会发现我们的低代码平台并没有提供 break、continue、return 等常见的短路结构,且可能因此对产品的表达能力抱有疑问。本文会解释不提供这三个语言结构的动机、原因,并解释其对表达能力不构成影响。
小知识
从表达能力上来说,break、continue 并没有从本质上增强语言的表达能力。
让我们考虑下面几个具体、典型的使用场景:
存在对列表的大量查询,希望使用
if和break来提高运行速度。此种代码类似for (int i = 0; i < list.length; i++) {
if (test(list[i])) {
// 处理代码
break;
}
}使用低代码平台的可视化逻辑编写,示意如下:

我们可以使用
ListFind等函数来替代三段式 for 循环,这样的代码读起来更直观,更不容易引入 bugs。示意如下: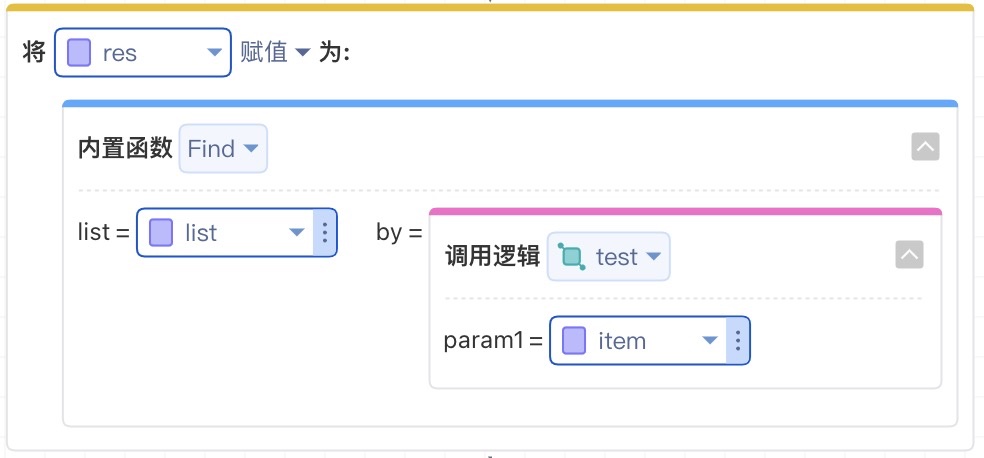
即先找到要处理的元素 res,后续再对 res(的成员)进行处理。
对列表前部元素做处理,在不满足时提前退出:
for (int i = 0; i < list.length; i++) {
// 对元素处理...
// 满足条件时结束
if (test(list[i])) {
break;
}
}此类处理流程也可由
takeWhile、dropWhile等高阶函数解决,这些函数的第一个参数是一个条件测试,不满足条件则终止对列表的迭代。以 Java 9 的takeWhile举例说明:Stream.of("cat", "dog", "elephant", "fox", "rabbit", "duck")
.takeWhile(n -> n.length() % 2 != 0) // 连续获取列表头部的项,直到字符串长度为偶数时停止
.forEach(System.out::println); // 对获取到的项做打印操作上述代码只会打印
cat和dog,而不会打印从elephant开始的项,因为elephant的长度是 8 ,是偶数。低代码平台目前将
takeWhile、dropWhile等函数定为 P1 优先级,将在后续版本陆续提供。跳过列表中的某些元素:
for (int i = 0; i < list.length; i++) {
if (test(list[i])) {
continue;
}
// 对元素处理...
}此类代码最简单的等价处理方法是不使用卫语句,代价是代码多一层缩进
for (int i = 0; i < list.length; i++) {
if (!test(list[i])) {
// 对元素处理...
}
}
上面我们介绍了使用 break 、continue 的 3 种典型场景和其替代方案。我们没有讨论复杂情形,例如在循环体的中间部分,在代码嵌套很深的地方使用 continue、break。但我们认为这种代码其实是难以维护的,应避免写出,尤其是在低代码产品中。
return 与之非常类似,并没有从本质上提高语言的表达能力。
完整细节
“小知识”章节介绍了一些典型场景和其替代方案。本章节为熟悉编程的专业技术人员提供更多的细节说明和支持材料。
针对大量查询的场景,我们应当认识到 List 这种顺序结构本身就不支持高速查询:
- 假设列表长度为
N,则不使用break时的查询时间为O(N)。 - 可假设待查询的元素在数组中的平均位置应在
1/2处,则使用break的时间复杂度为O(N/2)。
但 O(N) 与 O(N / 2)的复杂度在一个量级,并没有本质改善。
换一种思路,我们可以使用低代码平台提供的 Map 等高效查询结构,这样时间复杂度会降到 O(log N) 或 O(1),得到本质改善。
| 数据量级 | 复杂度 \ 时间消耗 | O(1) | O(log N) | O(N) | O(N/2) |
|---|---|---|---|---|
| 100 | 1 | 6.644 | 100 | 50 |
| 1 000 | 1 | 9.966 | 1 000 | 500 |
| 10 000 | 1 | 13.288 | 10 000 | 5 000 |
| 100 000 | 1 | 16.61 | 100 000 | 50 000 |
| 1 000 000 | 1 | 19.93 | 1 000 000 | 500 000 |
| 10 000 000 | 1 | 23.253 | 10 000 000 | 5 000 000 |
| 100 000 000 | 1 | 26.575 | 100 000 000 | 50 000 000 |
另外,从设计理念上来说, break、continue、return 等控制流结构是过程式、命令式的产物,而我们希望给用户带来声明式、函数式的产品体验,它会更面向数据流。
我们用一个小例子来描述控制流和数据流的区别。
如下的代码片段是典型的控制流结构,它声明了一个变量
x,此变量在不同条件下有不同的值。代码所做的事情便是在不同条件下用赋值语句去改变x的值。let x;
if (flag) {
x = 404;
} else {
x = 200;
}侧重数据流的代码则会这样描述:
let x = flag ? 404 : 200; // typescriptlet x = if flag then 404 else 200 -- Haskell
而函数式、声明式的一大特点正是面向数据流而非控制流编程。例如
- Java 等语言在用 foreach 循环代替三段式 for 循环,而这也带来了无法使用
break的“问题”:用户可以在 foreach 循环中使用return来代替continue,但无法找到break的替代。业界兴起的 map、reduce 编程范式亦不支持break、continue结构。 - 像 Haskell 这种纯函数式语言就没有提供
return这种让函数提前返回的结构——函数体的最后代码即为要返回的值。Haskell 非常极端,它甚至没有提供循环这种控制流(使用递归代替),也就无从谈起break、continue。这种极端行为的一个良性后果其实是让函数体简短、减少 bugs,易于维护。 - Scala 语言提供了循环,但其
break需要导入(import util.control.Breaks._)才能使用;从此设计也可看出它不与循环结构强绑定,也不被推荐使用。
(题外话:不提供 return、break、continue 后,很多不可达代码也一并不存在了。)
以上便是低代码产品尚未提供 break、continue、return 的原因。可总结为
- 削减过程式、命令式、控制流的味道,增加声明式、函数式、数据流的味道。
- 有同等替代用法,这些替代用法通常速度更优,或更结构化、不容易引入 bugs。