一、什么是 Language Server?
Language Server 是市面上常见的 IDE 针对某一门语言提供的错误检查(或叫错误诊断,通常包括语法、语义和建议)、自动补全、查找引用、跳转位置、重命名等功能的服务,它通常集成在 IDE 的这门语言插件中,以独立的本地进程方式运行。

这个概念最早是由微软的 VSCode 团队提出的,是为了支持语言检查等功能的开发语言与 IDE 本身的开发语言的独立,以及 CPU 和内存资源与 IDE 主进程的隔离。同时为了解决语言生态中多种语言插件与多个 IDE 集成的实现成本M * N的问题,他们制定了 Language Server Protocol,标准化了语言工具和代码编辑器之间的通信。目前已经有 VScode、Eclipse、Atom 等多个 IDE 的广泛支持。

目前该协议已经规定了多种常用语言功能的标准,主要包括:
- Diagnostics:错误检查(或叫错误诊断,通常包括语法、语义和建议)
- Completion:自动补全
- Find References:查找引用
- Goto Definition/Goto Type Definition/Goto Implementation:跳转定义或实现
- Rename/Prepare Rename:重命名相关
- Prepare Call Hierarchy/Call Hierarchy Incoming/Call Hierarchy Outgoing:列举调用栈
- Code Action/Refactor:代码重构,比如把几条语句提取成另一个函数
- Hover:悬浮提示
- Signature Help:函数签名提示
- Document Symbol:获取文档中所有符号
- Document Highlight:获取高亮范围
- Formatting/Range Formatting/On Type Formatting:格式化相关
- Folding Range/Selection Range:获取代码展开/选中范围
- …
二、CodeWave 智能开发平台中的 NASL 和 Language Server
许多零代码/低代码平台的核心部分实现是以可视化编辑器来读写一份 Schema(一般是 JSON 形式的配置),CodeWave 智能开发平台也不例外。
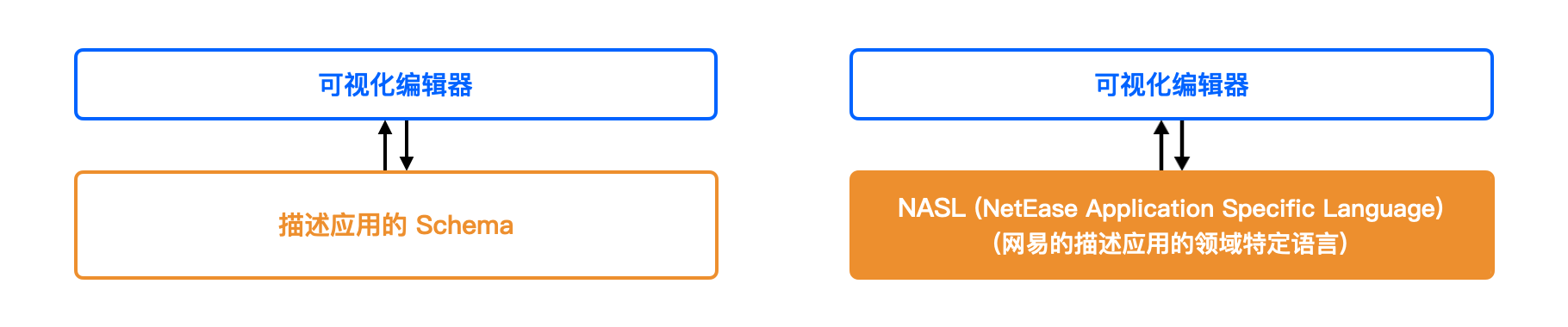
不同的是,为了满足用户能够搭建复杂的企业级应用,灵活表达业务逻辑需求,CodeWave 智能开发平台引入了表达式、控制流等常见的通用语言能力;为了打通各种数据库、外部接口数据模型和目标语言 JS 和 Java 代码的类型体系,CodeWave 智能开发平台设计了统一的静态类型系统。根据以上两点,CodeWave 智能开发平台的 Schema 已经具备了许多通用编程语言特性,可以被称为是一门编程语言,我们取名叫 NASL(NetEase Application Specific Language),全称的意思是:网易的搭建 Web 应用的专用语言。
不过,用户在CodeWave 智能开发平台中使用 NASL 灵活强大功能的同时,也容易像通用编程语言一样产生错误,比如:
- 赋值左右类型不一致,生成 Java 代码后编译会报错;
- 调用实体 create 逻辑时,传入的不是这种实体实例也明显会出问题;
- 前端组件双向绑定填的是一个计算表达式,生成如
v-model="a + 2"的 Vue 代码会报错; - …
所以产品需要提供更多排查错误、约束且友好的提示以及其他辅助功能。也就是上面提到的 Language Server 的主要功能。

以建设一门语言的思路,我们把这部分工作归结为 NASL Language Server 的建设,这部分也是低代码基础设施的核心重点和难点。
三、NASL 需要的语言特性
在讲 NASL Language Server 怎么建设之前,先介绍一下 NASL 需要的语言特性。
因为要生成 JS 和 Java 两套代码,NASL 语言特性的设计主要参考了 JavaScript、TypeScript 和 Java,辅助参考了 Scala、Kotlin、Python 等其他语言。
1. 统一的静态类型系统
NASL 是一门静态类型语言,类型分为三类:
- 原子类型:Boolean、Integer、Long、Double、String、Date、Time、DateTime 等
- 复合类型:结构体和枚举
- 泛型类型:带参数的结构体,如
List<T>、Map<K, V>等
2. 变量定义和逻辑定义
CodeWave 智能开发平台中的逻辑就是通用编程语言中的函数,包括输入参数、返回值和函数体。
3. 表达式
- 一元/二元表达式,包括常见的算术运算、逻辑运算、比较运算等
- 成员表达式,取某个复合类型变量的属性
- 赋值
- 调用逻辑
4. 控制流
- 顺序执行
- If 条件分支和 Switch 选择分支
- ForEach 循环分支和 While 循环分支
5. 命名空间
用户在定义实体、数据结构和枚举这些复合类型时可能有重名的情况,另一方面如果在复杂应用中定义的复合类型都是全局的,管理起来也很不方便。所以类似 Java 的 package 和 TypeScript 的 namespace, NASL 引入了应用内的命名空间概念。
以上是一些基本语言特性,除了泛型,总体类似 C 语言特性范围。下面是一些高级语言特性,如函数式编程、有限的面向对象编程等等。
6. 泛型函数
在提供了泛型类型List<T>之后,就必须要提供列表操作相应的内置函数库。
典型的场景是添加和删除列表项:
declare function Add<T>(list: List<T>, item: T): void;
declare function Remove<T>(list: List<T>, item: T): void;
...
7. 函数重载
在一些场景不想让用户学习因支持多种类型而产生的多个内置函数,就需要引入重载。
declare function AddDays(dateTime: Date, amount: Integer): Date;
declare function AddDays(dateTime: DateTime, amount: Integer): DateTime;
declare function Convert<T extends Boolean | Double | Long | String>(value: Integer): T;
declare function Convert<T extends DateTime | String>(value: Date): T;
...
再比如前端选择框单选/多选场景中的 value 类型不同,也需要重载的支持:
export class Select<T> extends Component {
constructor(
public options?: {
// 属性
size?: 'mini' | 'small' | 'normal' | 'large',
multiple?: false,
value?: string,
...
},
);
constructor(
public options?: {
// 属性
size?: 'mini' | 'small' | 'normal' | 'large',
multiple?: true,
value?: Array<string>,
...
},
);
...
}
8. 运算符重载
比如字符串直接用+拼接其他类型变量很方便,是一种典型的运算符重载。
declare function add(left: String, right: Any): String;
declare function add(left: Any, right: String): String;
...
9. 函数式编程
有了基础的列表增删改查操作之后,用户在处理排序、查找、过滤等列表操作时,还是要结合 If、ForEach 自己实现,和平时写代码的效率仍有明显差距。
而这些 API 在通用语言中一般都需要函数式编程的支持,比如下面这些例子:
declare function ListSort<T>(list: List<T>, by: (item: T) => Any, asc: Boolean): void;
declare function ListFind<T>(list: List<T>, by: (item: T) => Boolean): T;
declare function ListFindAll<T>(list: List<T>, by: (item: T) => Boolean): List<T>;
...
另一个典型的例子就是组件中的回调函数和事件绑定:
export class Select<T> extends Component {
constructor(
public options?: {
// 属性
dataSource?: List<T> | ((params: DataSourceParams) => Promise<List<T>>),
...
},
);
...
addEventListener(event: 'click', listener: (e: MouseEvent) => void);
addEventListener(event: 'change', listener: (e: ChangeEvent) => void);
}
const select = new Select({
dataSource: this.load,
});
select.addEventListener('change', this.onChange);
10. 面向对象继承
后面需要支持数据元管理,比如用户可以配置出 Email、URL、IDCard 等类型。他们显然都是 String 的子类型:
class Email extends String {
constructor(value: String);
@nasl.annotation.Rules([
pattern(/^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$/i),
])
validate(value: String): boolean;
}
class URL extends String {
constructor(value: String);
@nasl.annotation.Rules([
pattern(/^https?:\/\/(([a-zA-Z0-9_-])+(\.)?)*(:\d+)?(\/((\.)?(\?)?=?&?[a-zA-Z0-9_-](\?)?)*)*$/i),
])
validate(value: String): boolean;
}
class IDCard extends String {
constructor(value: String);
@nasl.annotation.Rules([
pattern(/^[1-9]d{5}(18|19|20|(3d))d{2}((0[1-9])|(1[0-2]))(([0-2][1-9])|10|20|30|31)d{3}[0-9Xx]$/),
])
validate(value: String): boolean;
}
这里用继承的好处是能方便的明确父子类型关系。比如在赋值和传递参数等场景下,子类型可以直接给父类型,但反过来则需要显式转换:
let email: Email = new Email();
let str: String;
str = email; // 直接赋值
email = Convert<Email>(str); // 反过来显式转换
11. 泛型型变(协变与逆变)
那么既然有了父子类型,又有泛型,就会产生泛型型变(协变与逆变)的问题。
协变(covariant)表示与泛型参数 T 的变化相同,而逆变(contravariant)表示与泛型参数 T 的变化相反。
一般来说,对于只有读操作的函数,我们希望函数参数兼容的类型更广一些,用协变;对于只有写操作的函数,函数体操作更泛化的类型容易出问题,用逆变。
function main() {
let stringList: List<String> = [new String('abc'), new String('小明')];
let emailList: List<Email> = [new Email('zhao@163.com'), new Email('hztest@corp.netease.com')];
printStringList(stringList); // 没有问题
printStringList(emailList); // 希望协变
printEmailList(emailList); // 没有问题
printEmailList(stringList); // 需要限制
addStringItem(stringList); // 没有问题
addStringItem(emailList); // 会有安全问题,email 列表中会加入普通 String
addEmailItem(emailList); // 没有问题
addEmailItem(stringList); // 希望逆变
}
function printStringList(list: List<String>) {
list.forEach((item) => console.log(item));
}
function printEmailList(list: List<Email>) {
list.forEach((item) => console.log(item));
}
function addStringItem(list: List<String>) {
list.add(new String('def'));
}
function addEmailItem(list: List<Email>) {
list.add(new Email('forrest@126.com'));
}
12. 类型操作器
在前面的组件的例子中,我们想从配置的数据源中,获取其中的 item 类型。用 TypeScript 表示如下:
declare function load(params: DataSourceParams): Promise<List<Student>>;
type GetItemTypeFromDataSource<T> = T extends List<infer U> | ((...args: any) => List<infer U>) ? U : never;
type ItemType = GetItemFromDataSource<typeof load>; // Student
13. 其他
还有许多其他局部特性,就不在这里一一列举了。
可能这里有同学会问,你们不是做的低代码吗,为什么要引入这么多高级语言特性,会不会增加用户的学习成本和复杂度?
答案是否定的。一方面,引入的语言特性会以三种形式在低代码中体现:
- 全部暴露让用户定义和使用,如上面的复合类型和逻辑;
- 只让用户使用,定义是由低代码的内置库提供的,如上面的泛型类型、泛型函数;
- 作为语言的底层设施,用户不会直接接触到该概念,但在可视化交互中能体会到或者完全感知不到,如数据查询的语句链路等。
所以用户接触到高级语言特性的入口一定是我们简化过的。
另一方面,恰恰相反的是,用户在搭建复杂应用中,表达复杂需求用合适的高级语言特性才会更简单。假设在内置库都预置好的情况下,让你用 C 语言写一段 Web 应用的复杂逻辑,和用成熟的如 TypeScript 的高级语言相比,哪个更简单?
四、Language Server 的建设路线
自研路线
首先能想到的方案是自研一个 Language Server。与通用编程语言类似(通用编程语言的这部分功能一般是实现在编译器中),基本思路如下:
- 首先,Language Server 的输入是 NASL AST,输出是错误检查、自动补全等信息;
- 在初次拿到 AST 后,Language Server 会生成符号表和作用域等相关缓存数据;
- 接下来就是有多少语言特性,就要投入多少成本,比如上面列举的基础表达式、函数式编程、型变、重载等诸多特性;
- 最后整理成最终的错误检查、自动补全等信息;
- 另外还需要处理 AST 增量修改的场景。

可以看出,主要实现成本集中在第 3 点。这里一方面高级语言特性本身比较复杂,另一方面语言特性之间往往不是独立的。比如:
- 泛型和继承,需要把型变的问题处理妥当;
- 泛型和函数式编程,需要把泛型函数、泛型类型的函数字段等一系列问题搞定;
- 重载和函数式编程,需要计算函数实参的类型、判断重载到哪个函数里(比如前面的绑定事件例子);再遇上前面的泛型和继承,就很酸爽了;
- …
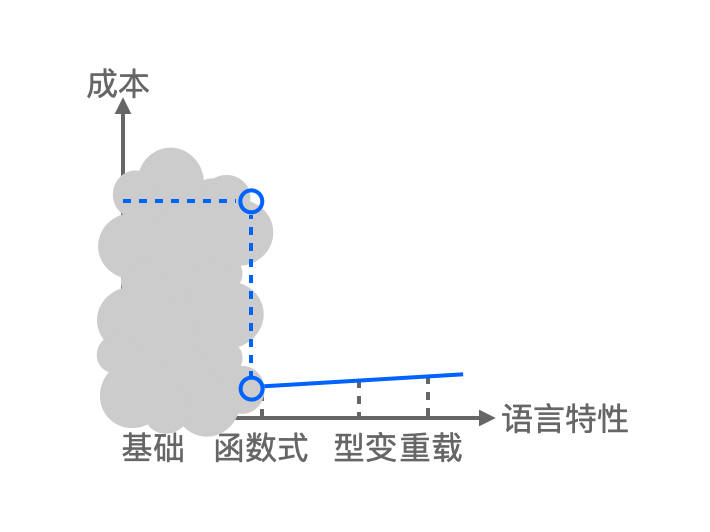
也就是说,随着更多语言特性的引入,实现成本会陡然上升。不亚于研发一门通用编程语言的成本(一般综合编译器前后端和内置库,大约30-60人左右)。

那么这种路线成本这么高,还有没有别的方案了?
宿主语言路线
有。另一种路线是以成熟的通用编程语言为宿主,借助它的 Language Server 来实现我们的 NASL Language Server。
什么是宿主语言?一般在提到内部 DSL(Embedded DSL 或 Internal DSL)时,我们会关心它是建立在哪一门通用编程语言之上的。比如远古框架 jQuery:
$('#user_panel')
.click(hidePanel)
.slideDown()
.find('button')
.html('follow');
它的语义是:
- 获取 #user_panel 节点(jQuery 实例);
- 设置点击后隐藏它(传入函数);
- 向下动效展开(调用函数);
- 然后找到它下面的所有 button 节点(jQuery 实例);
- 为这些按钮填充 follow 内容(字符串)。
一般来说,内部 DSL 的语法和基础语义是宿主语言的子集,可以共享宿主语言的编译与调试工具等基础设施。
因此,如果 NASL 是某一门语言的子集,就可以以该语言为宿主语言,借用它的 Language Server 设施。那么就有以下一条路线:
- NASL AST 翻译成这门宿主语言的代码 + SourceMap;
- 在 AST 初始化和变更时,捕获宿主语言的错误检查、自动补全等信息(带有位置信息);
- 适配层根据位置信息,结合 SourceMap 在 NASL AST 中找到原来的节点;
- 根据找到节点的上下文,再补充成最终的错误检查、自动补全信息等。(这部分不需要关心语言特性的处理,只需关注 NASL 节点上下文补充信息即可)

可以看出,这条路线的后期成本肯定会降低。但前期未知性的问题较多:
- 首先,NASL 吸收了 JS/Java 的各种特性,是不是某一门语言的子集了?
- 前期处于迷雾状态,不知道有多少坑,实现成本不明朗。
- 这种实现是黑盒模型,后面会不会遇到不可持续迭代的问题?比如:
- 吐出的原始信息够不够我们用?
- 我们想做类 SQL 的语义,能不能支持?
- 文本式的语言能力能不能满足我们可视化场景的需求?
- ...
宿主语言的选择
首先针对第 1 个问题,我们调研了许多语言,最主要的是 Java、TypeScript 和 Scala。就语言特性方面来说:Java < TypeScript < Scala。
以它们为宿主语言的主要问题是:
- Java:不能 hold 住许多前端泛型组件的场景,也没有灵活的类型操作器;
- TypeScript:数值类型只有 number 类型和 Java 的 Integer/Long/Double 多种类型设计有出入,Structural Typing 和 Java 的 Nominal Typing 有出入;
- Scala:团队技术主要的体系不在这一块,维护成本较高,招聘门槛高。
相对来说,TypeScript 的问题较轻,需要尝试看能不能用一些技术手段规避掉。
另外,根据我们对 TypeScript Playground 和 Monaco Editor 的观察,TypeScript Language Server 还有一个明显的优势,就是能以 Worker 的形式在浏览器中运行。因为CodeWave 智能开发平台是 Web IDE,对 Language Server 实时性要求很高,放在浏览器端可以大大减轻服务器资源。

五、基于 TypeScript 宿主语言的核心实现
TypeScript 所有的语言设施其实就在我们平时使用的node_modules/typescript/lib下:

它主要有以下设施:
typescript.js:TypeScript 核心包,就是编译器 API,可以在 JS 引入,然后解析和编译一段 TypeScript 文本;
tsc.js:TypeScript Compiler,就是我们平时经常使用的编译成 JS 的命令行;
typescriptServices.js: TypeScript Services,提供较多的语言服务 API,用于 IDE 的插件开发,比如 Monaco Editor 和 VSCode 内置的 TypeScript 插件都基于这个文件包装;
tsserver.js: TypeScript Language Server,可独立运行的服务器,stdin/stdout JSON 形式的协议,支持 Node.js 和浏览器。
这些在 TypeScript Wiki 讲得比较清楚。
以 TypeScript 核心包为突破口
最简单的是 TypeScript 核心包,官方示例比较详细,它在编译的时候,能直接返回错误检查信息,我们就以它为突破口,打通链路,驱散迷雾。
首先,列举了几个不同难度的场景:1. 基本逻辑;2. 数据查询;3. 外部 SQL;4. 页面组件。
1、将这几个场景的 NASL AST 翻译成 TypeScript + SourceMap。
比如这样一段简单的包含 If 逻辑的 NASL AST:
{
"concept": "Logic",
"name": "logic1",
"params": [
{
"concept": "Param",
"name": "param1",
"typeAnnotation": {
"concept": "TypeAnnotation",
"typeKind": "primitive",
"typeNamespace": "nasl.core",
"typeName": "Integer",
"typeArguments": null
}
}
],
"returns": [],
"variables": [],
"body": [
{
"concept": "Start",
"label": "开始"
},
{
"concept": "IfStatement",
"label": "条件分支",
"folded": false,
"test": {
"concept": "BinaryExpression",
"left": {
"concept": "Identifier",
"name": "param1"
},
"right": {
"concept": "NumericLiteral",
"value": "3",
"typeAnnotation": {
"concept": "TypeAnnotation",
"typeNamespace": "nasl.core",
"typeName": "Integer",
"typeArguments": null
}
},
"operator": ">"
},
"consequent": [],
"alternate": []
},
{
"concept": "End",
"label": "结束",
"folded": false
}
],
"playground": []
}
翻译成 TypeScript 文件 /embedded/someApp/logics/logic1.ts 如下:
namespace app.logics {
export function logic1(param1: nasl.core.String) {
if (param1 > new nasl.core.Integer(3)) {
}
return;
}
}
SourceMap 的结构是 Map<BaseNode, { code: string, range: Range }>,
比如上面 name=param1 的 Identifier 的 SourceMap 是:
{
code: 'param1',
range: {
start: { line: 3, character: 12, offset: 102 },
end: { line: 3, character: 18, offset: 108 },
}
}
而 BinaryExpression 的 SourceMap 是:
{
code: 'param1 > new nasl.core.Integer(3)',
range: {
start: { line: 3, character: 12, offset: 102 },
end: { line: 3, character: 45, offset: 135 },
}
}
2、这时将翻译好的 TypeScript 代码丢进核心包,它会报一条错误和相应的位置。
Operator '>' cannot be applied to types 'String' and 'Integer'. { "start": { "line": 3, "character": 12 }, "end": { "line": 3, "character": 45 } }
3、接下来从 SourceMap 所有点中,找到最接近错误信息的位置的节点 findClosestNode。上面例子中即为 BinaryExpression 那个节点。
4、实现 translator 函数,用正则表达式等方式,将上面的英文转换成产品所想展示的错误信息。根据节点信息,红框并显示上下文,比如所在逻辑为 logic1。最终效果如下:

实现了针对上述场景的几个 Demo,就基本验证了很多问题:
- 前期实现成本不高;
- 吐出的原始信息基本够用;
- TypeScript 能处理 Java 语言特性的问题
最后一个点,是这样处理的:
- 干脆不用 TypeScript 的原生类型,自己用 class 定义 NASL 需要的基本类型:
export class Integer {
accept: 'Integer';
constructor(num?: number);
}
export class Double {
accept: 'Double' | 'Integer' | 'Long';
constructor(num?: number);
}
export class Long {
accept: 'Double' | 'Integer';
constructor(num?: number);
}
- 在 Structural Typing 下用唯一字段
__name来模拟 Nominal Typing:
namespace app.dataSources.defaultDS.entities {
@nasl.annotation.Entity()
export class Student {
__name: 'app.dataSources.defaultDS.entities.Student';
id: nasl.core.Long;
...
}
}
- TypeScript 中没有运算符重载,干脆不用普通的
+-*/,直接用函数重载来模拟:
declare function add(left: Integer, right: Integer): Integer;
declare function add(left: Integer, right: Long): Long;
declare function add(left: Integer, right: Double): Double;
declare function minus(left: Integer, right: Integer): Integer;
declare function minus(left: Integer, right: Long): Long;
declare function minus(left: Integer, right: Double): Double;
declare function multiply(left: Integer, right: Integer): Integer;
declare function multiply(left: Integer, right: Long): Long;
declare function multiply(left: Integer, right: Double): Double;
declare function divide(left: Integer, right: Integer): Integer;
declare function divide(left: Integer, right: Long): Long;
declare function divide(left: Integer, right: Double): Double;
攻坚 Language Server 全部能力
上面的 Demo 只有错误检查功能,其他的 Language Server 能力是集成在 typescriptServices.js 和 tsserver.js 中的。接下来就需要实现完整的 Language Server 能力。
目前我们在各种渠道发现有 4 个项目中是比较成熟地使用了 TypeScript Language Server 的大部分能力,所有我们从这些项目入手攻坚:
1. MonacoEditor
TypeScript Playground 就是基于它实现的,MonacoEditor 官网也有许多 TypeScript Demo。从实现效果来说和我们想要的最接近。
我们需要做的是,找出 MonacoEditor 中封装 Language Server 能力的入口,然后最好能拆出来。因为一个 MonacoEditor 很庞大,包含了许多其他我们并不需要的编辑器功能。
2. VSCode 内置的 TypeScript 插件
直接进攻 VSCode 编辑器也是很好的一个方向,VSCode 项目本身是开源的,也有许多编写插件的示例。
但它是 Node.js 环境,VSCode 中包装了许多 vscode-language-client, vscode-language-server 等 package,要拆解起来还是有一定的复杂度。
3. tsserver
node_modules/typescript/lib 下 tsserver 可以直接启动,而有个入口文档,与 TypeScript 核心包一脉相承。
可以用命令行启动的 tsserver,以 stdin/stdout JSON 形式的协议进行通信,同时支持 Node.js 和浏览器。但语言协议是 TSP(TypeScript Server Protocol)协议,非标准的 LSP 协议。
4. 社区提供的标准 LSP 协议 TypeScript Language Server
是在 3 的基础上包装了 LSP 协议。
经过一段时日的研究,我们发现 2 中 VSCode 包装的成本太高。4 是 3 的包装版。最终我们重点研究 1 和 3。
测评下来,在 240 个 class(实体 + 枚举 + 数据结构)+ 240 个 logic + 80 个 view = 560 个 ts 文件的情况下:
| MonacoEditor | tsserver | |
|---|---|---|
| 启动时全量检查 | 75s | 2.6s |
| 单文件小修改 | 1s | 1.3s |
| 修改一个被大量引用的文件 | x | 1.3s |
| 多个文件同时发生修改 | x | 1.2s |
| 平均占用内存 | 440MB | 160MB |
MonacoEditor 直接集成进来性能有较大问题。最终我们选择离核心包最接近的 tsserver。
包装 ts-worker
Language Server 想在浏览器中跑,并且不阻塞用户界面主线程,就需要利用 Web Worker 新开线程。JavaScript 是单线程的,Web Worker 是浏览器提供的一种新开线程运行脚本的技术,Worker 线程可以在不阻塞用户界面的情况下执行任务。它和主线程主要用 postMessage 通信。
这部分不是很复杂,我们基于 postMessage 包装了一套 Messager,然后直接在 Worker 内外实例化:
// ts-worker 中
const messager = new Messager({
protocol: 'ts-worker',
sender: 'worker',
context: this,
getReceiver: () => self,
getSender: () => self,
});
// 外部
const messager = new Messager({
protocol: 'ts-worker',
sender: 'ide',
context: this,
getReceiver: () => worker as any,
getSender: () => worker as any,
handleMessage({ data }: any) {
if (data && data.event === 'publishDiagnostics') {
diagnosticManager.pushAll(naslServer._resolveDiagnosticRecords(data.records));
}
},
});
最终架构
最终实现的架构如下:
- 可视化编辑器和 NASL Language Server 均在浏览器中运行;
- TS Language Server 以 Worker 的形式运行;
- NASL Language Server 中的 Adapter 计算量不大,并且和可视化编辑器是共享内存的,所以暂时没有切出的必要。
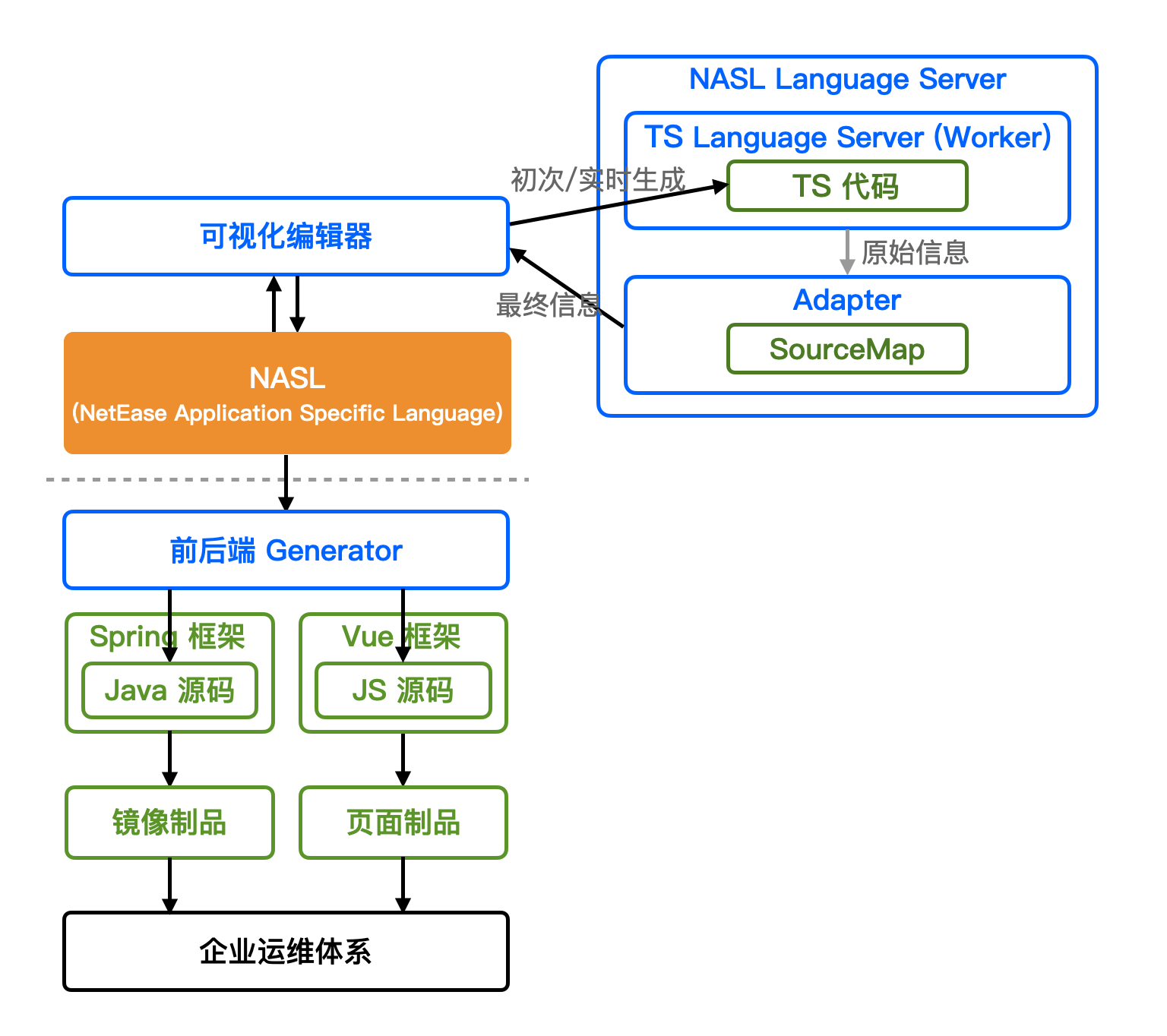
使用时的数据流向是:
- 用户在可视化编辑器初次全量加载/实时变更编辑 NASL;
- 可视化编辑器初次全量/实时差量生成 TS 代码,并请求 NASL Language Server;
- NASL Language Server 的 Adapter 向 TS Language Server(Worker)请求信息;
- Adapter 通过上下文整理出最终信息,返回给可视化编辑器。
Node.js 同构 NASL Language Server 备选
考虑到在浏览器中运行 Language Server 特别依赖用户打开浏览器,另外不确定会不会有其他方面的局限。于是我们同时做了一个 Node.js 同构的 NASL Language Server 服务的备选方案。
- TS Language Server 切成 Node.js 的 Worker;
- Adapter 通过一些打包处理兼容 Node.js 即可。
即时不用于线上产品,也可以做自动化测试。
最终效果
最终方案上线之后,产品的错误检查、自动补全、重命名等语言方面的实时性和准确性体验有了明显提升。
同时开发成本有明显的降低,比如需要函数式编程机制的列表操作 API,原来预估 2 人 1.5 个月的语言研发工作,现在只要 1 人 1 星期就能完成。
后续规划
基于新的这版 Language Server 继续优化产品底层的语言机制,增强产品的类型检查、类型提示等体验,比如:前端相关类型提示、数据查询类型爆炸、数据元管理机制等问题。
另外当前的一个主要挑战是 NASL 中有许多用户方便使用的隐式转换规则,但编译 Java 时需要更多类型信息,目前 TS Language Server 还不能快速全量获取,需要进一步调研处理。